k3s 初探
以最小可运行示例记录 k3s 的安装、启动与基础使用流程,帮助快速搭建轻量 Kubernetes 环境。

本文将在一个有3台服务器的迷你集群中简单测试 k3s 的安装和使用。
参考自:
https://www.ywbj.cc/?p=1418 https://docs.k3s.io/zh/quick-start
安装
首先,我们在 node0 上安装 k3s 的 master 节点:
1
curl -sfL https://get.k3s.io | sh -
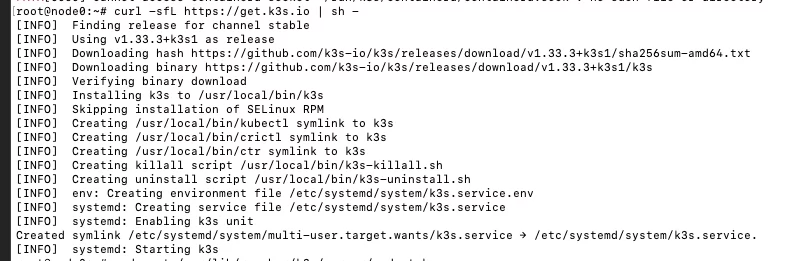
master 节点安装完成后,k3s 会自动生成一个 token 文件 /var/lib/rancher/k3s/server/node-token,我们可以使用这个 token 来加入其他节点。
k3s 的 node token 是一个用于集群节点间安全通信的令牌,只有拥有正确 token 的节点才能加入集群,防止未授权访问。
因此,我们在 node0 执行
1
sudo cat /var/lib/rancher/k3s/server/node-token
来获取 token

接下来,用刚刚获取的 token 在 node1 和 node2 上安装 k3s 的 worker 节点:
在 node1 和 node2 上分别执行:
1
2
3
TOKEN=K104010e617e32c94af28fb5b1bc6a6e1c8ee9eaccae64cbadda79a819f852ab822::server:2be2cb5985bc549e94f1dd483bd41342
IP_OF_NODE0=192.168.1.227
sudo curl -sfL https://get.k3s.io | K3S_URL=https://$IP_OF_NODE0:6443 K3S_TOKEN=$TOKEN sh -
TOKEN 和 IP_OF_NODE0 分别替换为之前获取的 token 和 node0 的 IP 地址。
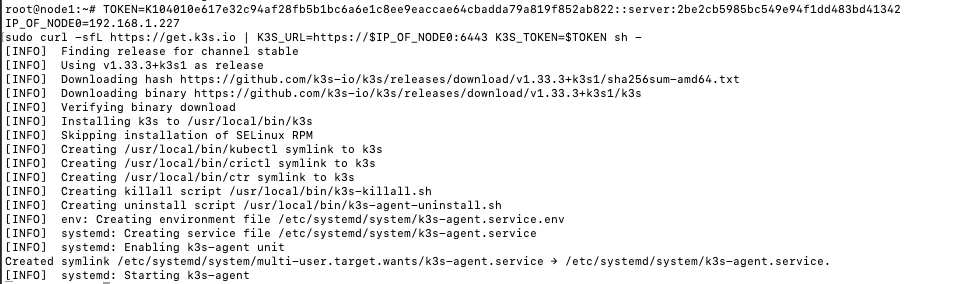
从节点运行完成后,在 node0 运行
1
sudo kubectl get nodes
查看集群节点状态:

备注1:
k3s 和 kubectl 的关系如下:
k3s 是一个轻量级的 Kubernetes 发行版,用于快速部署和运行 Kubernetes 集群。 kubectl 是 Kubernetes 的命令行工具,用于管理和操作 Kubernetes 集群,比如查看节点、部署应用等。
- k3s 负责运行和管理集群,kubectl 负责与集群交互和操作。
- 安装 k3s 后会自动生成 kubeconfig 文件,kubectl 通过该文件连接和管理 k3s 集群。
- kubectl 可以管理任何兼容 Kubernetes API 的集群,包括 k3s。
备注2:
k3s 安装脚本会自动安装服务,安装完毕后会自动启动 k3s 服务。可以使用以下命令查看 k3s 服务状态:
1
sudo systemctl status k3s

如果需要停止或重启 k3s 服务,可以使用以下命令:
1
2
3
sudo systemctl stop k3s # 停止 k3s 服务
sudo systemctl start k3s # 启动 k3s 服务
sudo systemctl restart k3s # 重启 k3s 服务
使用
我的测试环境下集群状态如下:
1
2
3
4
5
root@node0:~# sudo kubectl get nodes
NAME STATUS ROLES AGE VERSION
node0 Ready control-plane,master 14h v1.33.3+k3s1
node1 Ready <none> 14h v1.33.3+k3s1
node2 Ready <none> 114s v1.33.3+k3s1
下面我将测试运行一个容器,确保这个容器在一个节点上运行,当这个节点宕机后,容器会自动迁移到其他节点上。
我们使用 kubernetes 的 Deployment 来管理容器的部署和运行。
Deployment 是 Kubernetes 中的一种控制器资源,用于管理和自动化应用的部署、升级和扩缩容。
主要功能:
- 保证指定数量的 Pod 始终运行
- 支持滚动升级和回滚
- 自动重建崩溃或被删除的 Pod
- 支持扩容和缩容
典型场景: 你只需声明一次应用的期望状态(如副本数、镜像等),Deployment 会自动维护实际状态与期望状态一致。
我们创建一个简单的 Deployment,运行一个 nginx 容器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion: apps/v1 # 指定使用 Kubernetes 的 apps/v1 API 版本。
kind: Deployment # 资源类型为 Deployment,用于管理一组 Pod 的生命周期。
metadata: # 资源的元数据,这里设置了 Deployment 的名字为 test-deployment
name: test-deployment
spec: # Deployment 的具体规格和期望状态。
replicas: 1 # 希望有 1 个 Pod 实例在集群中运行。
selector: # 用于选择哪些 Pod 属于这个 Deployment。这里通过标签 app: test 进行匹配。
matchLabels:
app: test
template: # Pod 模板,定义 Pod 的内容。
metadata: # 给 Pod 加上标签 app: test,用于 selector 匹配。
labels:
app: test
spec: # Pod 的具体规格。
containers: # 定义 Pod 内的容器列表。
- name: test-container
image: nginx # 你可以换成自己的测试镜像
将上面的内容保存为 test-deployment.yaml 文件,然后在 node0 上执行以下命令来创建 Deployment:
1
sudo kubectl apply -f test-deployment.yaml

命令已经成功创建了名为 test-deployment 的 Deployment 资源。 现在 Kubernetes 会自动在集群中运行一个 nginx 容器,并确保始终有一个副本在线。
接下来,我们可以使用以下命令查看 Deployment 的状态:
1
sudo kubectl get deployments
初始状态看到镜像没有准备好:

使用
1
kubectl get pods
命令查看 Pod 的状态:

可以看到 Pod 的状态是 ContainerCreating,表示容器正在创建中。
使用
1
kubectl describe pod test-deployment-66f9f858dc-lcplk
命令(替换 test-deployment-66f9f858dc-lcplk 为 get pods 查询到的 Pod 名称)来查看 Pod 的详细信息。
如果看到无法拉取 rancher/mirrored-pause:3.6 镜像,具体报错为网络请求失败(EOF),通常是网络无法访问 Docker Hub 或镜像仓库。请检查网络连接或镜像源配置。
备注:
rancher/mirrored-pause:3.6 镜像是 Kubernetes 集群中用于Pod 沙箱(Pod Sandbox)的特殊镜像。 它不是运行你的业务容器,而是作为 Pod 的“基础容器”,用于为 Pod 提供网络和命名空间隔离。 每个 Pod 启动时,都会先启动一个 pause 容器,其他业务容器都运行在这个 pause 容器的网络和命名空间下。如果无法拉取,可以尝试更换 k3s 的镜像源。
如果网络正常,稍后可以看到 Pod 的状态变为 Running。
1
sudo kubectl get pods

成功🎉
成功状态下查看 Pod 的详细信息,应该看到:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
root@node0 ~# sudo kubectl get pods
NAME READY STATUS RESTARTS AGE
test-deployment-66f9f858dc-6k5s6 1/1 Running 0 4m36s
root@node0 ~# kubectl describe pod test-deployment-66f9f858dc-6k5s6
Name: test-deployment-66f9f858dc-6k5s6
Namespace: default
Priority: 0
Service Account: default
Node: node1/192.168.1.185
Start Time: Wed, 06 Aug 2025 04:52:41 +0000
Labels: app=test
pod-template-hash=66f9f858dc
Annotations: <none>
Status: Running
IP: 10.42.1.19
IPs:
IP: 10.42.1.19
Controlled By: ReplicaSet/test-deployment-66f9f858dc
Containers:
test-container:
Container ID: containerd://842da0a16935022a6db0dacd5feb5af4f2016656ce2ba428973f2658fb3012d8
Image: nginx
Image ID: docker.io/library/nginx@sha256:84ec966e61a8c7846f509da7eb081c55c1d56817448728924a87ab32f12a72fb
Port: <none>
Host Port: <none>
State: Running
Started: Wed, 06 Aug 2025 04:53:27 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-h6v4r (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-h6v4r:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
Optional: false
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4m41s default-scheduler Successfully assigned default/test-deployment-66f9f858dc-6k5s6 to node1
Normal Pulling 4m28s kubelet Pulling image "nginx"
Normal Pulled 3m55s kubelet Successfully pulled image "nginx" in 33.723s (33.723s including waiting). Image size: 72223946 bytes.
Normal Created 3m55s kubelet Created container: test-container
Normal Started 3m55s kubelet Started container test-container
root@node0 ~#
如果想查看 Deployment 的详细信息,可以用:
1
sudo kubectl describe deployment test-deployment
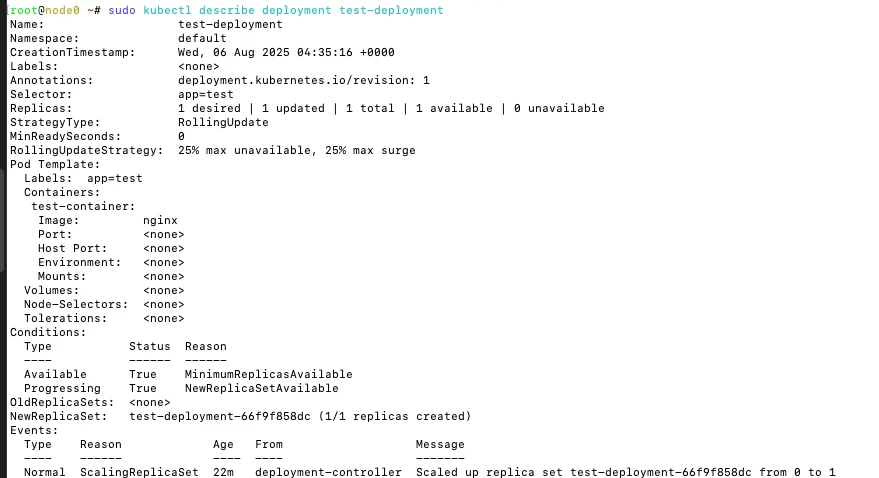
测试节点宕机后容器迁移
现在我们来测试一下,当运行容器的节点宕机后,容器是否会自动迁移到其他节点上。
首先查看当前 Pod 的状态,查看它运行的位置
1
sudo kubectl get pods -o wide

可以看到 Pod 正在 node1 上运行。
如果 pod 恰好被分配到 node0, 我们暂时无法测试节点宕机,因为在我们的集群中 node0 是 master 节点,master 宕机后无法管理集群。
这种情况可以删除 Pod, 随后 k3s 会自动重新调度 Pod 到其他节点上。命令类似:
1
2
sudo kubectl delete pod test-deployment-66f9f858dc-f6vff
sudo kubectl get pods -o wide
你应该看到 Pod 被重新调度到其他节点运行。
我们现在测试正在运行 pod 的 node1 宕机时会发生什么:
我们直接关闭 node1
1
sudo shutdown -h now # 在 node1 上执行,谨慎执行,以为此操作会导致 node1 立刻关机
稍等几分钟后回到 node0 上查看节点状态
1
2
3
4
5
root@node0 ~# sudo kubectl get nodes
NAME STATUS ROLES AGE VERSION
node0 Ready control-plane,master 33m v1.33.3+k3s1
node1 NotReady <none> 29m v1.33.3+k3s1
node2 Ready <none> 29m v1.33.3+k3s1
可以看到 node1 的状态变为 NotReady,表示它已经不在集群中了。
接下来查看 Pod 的状态:
1
sudo kubectl get pods -o wide

尽管node1 宕机了,但 Pod 仍然显示为 Running 状态,并且还是在 node1 上。这时因为 Kubernetes 默认有容忍时间,在一段时间后才会驱逐 Pod,并重新调度到其他节点。如果没有设置容忍时间,默认会等待 5 分钟(300 秒)后才会驱逐 Pod。
再等一会儿可以看到

我们发现 k3s 自动开始 terminate node1 上的 Pod,并将其重新调度到 node0 上。

看到 Pod 状态变为 Running,并且现在运行在 node0 上。
进阶配置(高可用模式)
未完待续