cxl相关论文整理
持续整理近年顶会中的 CXL 相关论文,按主题汇总研究方向、代表工作与阅读要点。

1
Xinjun Yang, Yingqiang Zhang, Hao Chen, Feifei Li, Gerry Fan, Yang Kong, Bo Wang, Jing Fang, Yuhui Wang, Tao Huang, Wenpu Hu, Jim Kao, Jianping Jiang:
Unlocking the Potential of CXL for Disaggregated Memory in Cloud-Native Databases.
SIGMOD Conference Companion 2025: 689-702
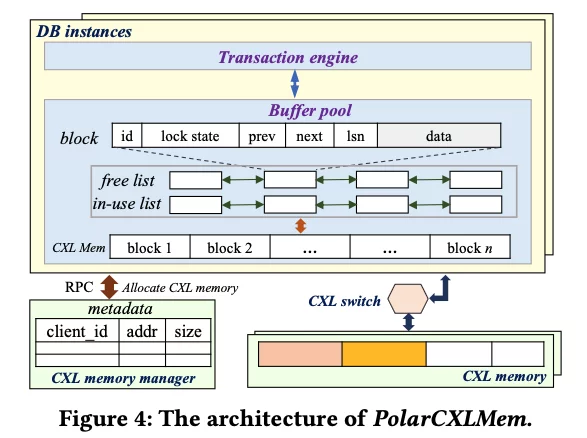
首个使用cxl交换机实现cxl内存池的数据库系统。
解决的问题:
传统基于rdma内存池的数据库存在以下问题:
- 读写放大和带宽浪费。页面粒度在内存池和本地dram之间迁移数据页时,可能导致不必要的数据传输和带宽占用。
- 崩溃恢复慢,崩溃恢复时需要在计算节点本地dram重建复杂的元数据结构
本文的解决方案:
取消计算节点本地dram缓冲区,直接用load/store访问cxl内存池,因此减少读写放大和带宽浪费。由于大量数据直接从cxl内存池读写,因此崩溃恢复时不再需要重建复杂的元数据结构。本文在cxl内存池中设计了一个比较简单的wal日志系统。
本文还设计了一个多主节点写入数据时的数据一致性保证机制。但是也比较简单,依赖于一个独立的cxl内存池元数据管理节点,每个计算节点读写内存池需要通过rpc与独立的元数据管理节点通信。
2
Yunyan Guo, Guoliang Li:
A CXL-Powered Database System: Opportunities and Challenges.
ICDE 2024: 5593-5604
没有提供特定的方法,只是提出了一些挑战和机会。
DBMS 在以下几个方面可以利用CXL优化:
- 缓冲池扩展
- 内存弹性
- 快速数据恢复
- 索引优化
缓冲池扩展
A.挑战1:混合缓冲池构建
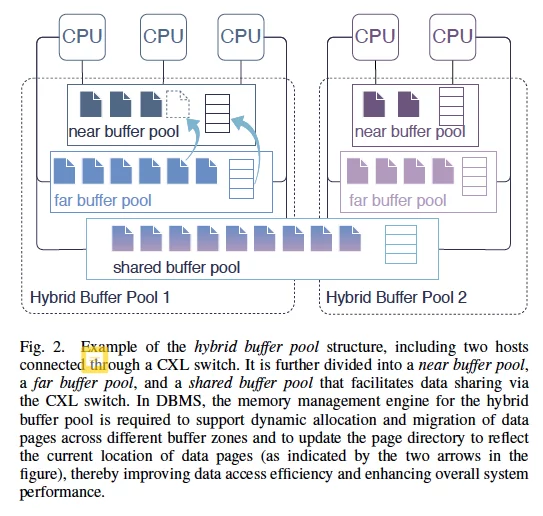
值得考虑的点:
- 数据放置位置、迁移策略
- 解耦内存和cpu
B.挑战#2:动态数据页分配。
值得考虑的点:
- 如何动态定位和分配页面
- 页目录的设计和维护
- 行存储和列存储的决策
C.挑战#3:实现多写一致性的细粒度内存共享。
值得考虑的点:
- 细粒度数据同步、冲突解决以及事务原子性和持久性的维护
内存弹性
A.挑战#4:弹性混合缓冲池。
值得考虑的点:
- 混合分析处理(HTAP)或多模态数据场景下,缓冲池需求变化很大,准确预测混合缓冲池的内存需求
- 降低内存分配的延迟的影响
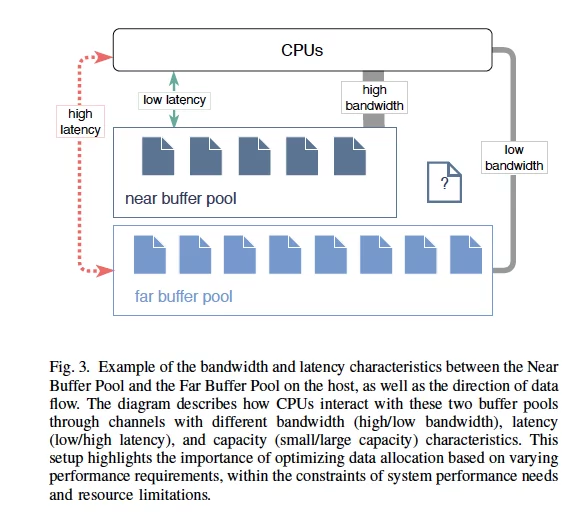
B.挑战#5:优化近远内存分配。
值得考虑的点:
- CXL 协议为 DBMS 提供了动态内存分配功能,但是要设计分配策略以平衡近内存和远内存的优势
C. 挑战#6:冷热数据智能分层。
值得考虑的点:
- 如何适应缓冲池大小的动态变化并做出数据分层决策
快速数据恢复
A. 挑战#7:双重检查点机制。
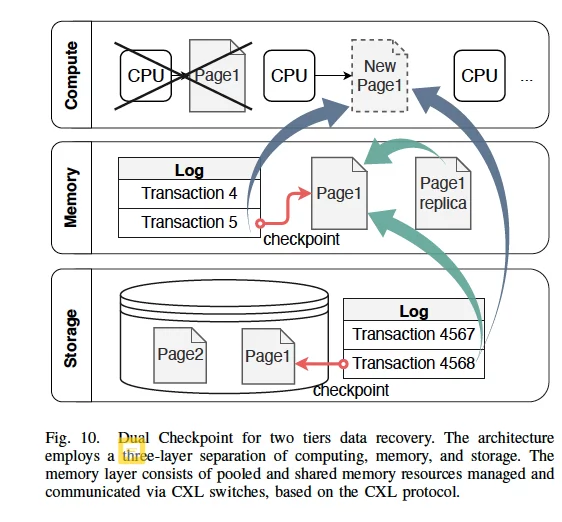
值得考虑的点:
- 用内存检查点(如果内存节点处于活动状态)或存储检查点恢复计算节点,用副本或存储检查点恢复内存节点
B.挑战#8:同步共享内存中的脏页。
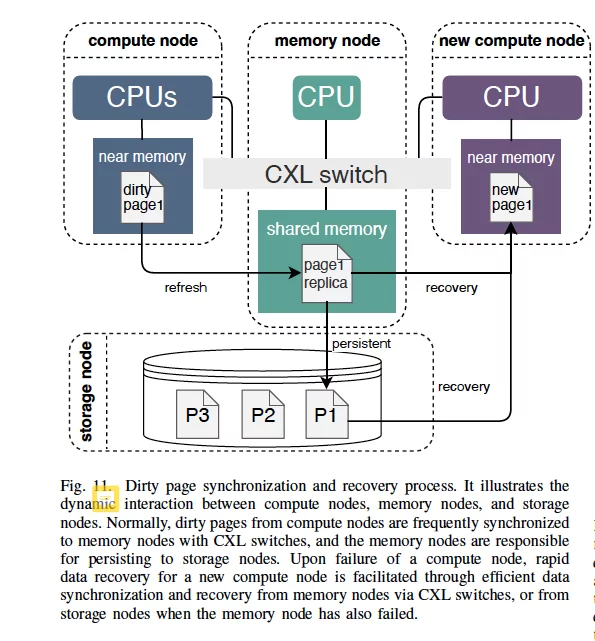
值得考虑的点:
- 把存储节点的脏页列表存储在CXL共享内存中,以便快速恢复
C. 挑战#9:使用 CXL 和持久内存强制提交。
值得考虑的点:
- 用cxl直接将事务写入持久内存,避免额外的日志
索引优化
A.挑战#10:B+树节点的内存分配。
值得考虑的点:
- 综合考虑B+树内部节点和叶子节点的放置。对于读为主或写为主的工作流,最佳放置策略不同。
B.挑战#11:数据修改的动态内存分配。
值得考虑的点:
- B+树节点动态调整时的内存分配成本预测
- 节点放置和对动态工作负载的适应性
C.挑战#12:增强结构更新的索引并发性。
值得考虑的点:
- 索引并发预取
- 乐观并发控制
- 合理利用CXL提供的共享内存和缓存一致性能力
3
Jie Zhang, Xuzheng Chen, Yin Zhang, Zeke Wang:
DmRPC: Disaggregated Memory-aware Datacenter RPC for Data-intensive Applications.
ICDE 2024: 3796-3809
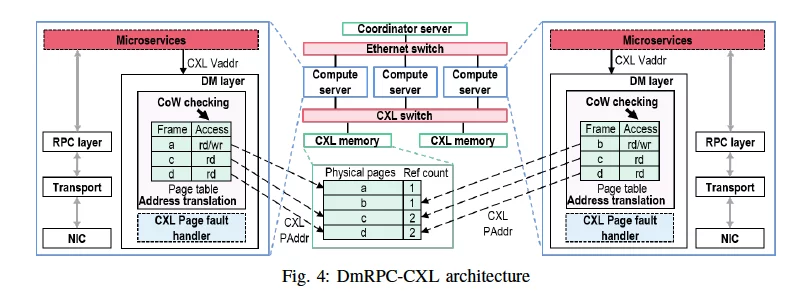
设计了一个基于CXL的RPC系统。传统RPC按值传递数据,造成额外数据拷贝;或按引用传递数据,但需要上层应用处理复杂的数据一致性问题。
解决方案:
利用共享内存按引用传递数据,同时设计一个页面粒度的写时复制机制,避免写写冲突,对上层应用隐藏一致性的细节。
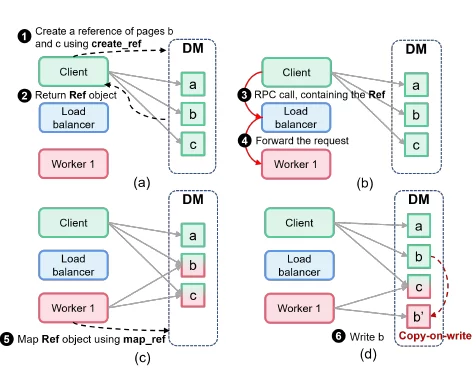
本文使用共享内存来避免rpc输入数据和输出数据的拷贝,同时允许直接修改数据数据(写时复制),进一步减少不必要的数据拷贝。除了输入数据和输出数据以外,其他命令还是使用基于以太网的传统RPC发送的。
本文没有使用CXL的高级特性。实验是在一个双socket的服务器上进行的,其中一个CPU执行客户端和服务端的所有进程,内存分配全部在另一个socket完成。本文通过降低内存频率的方式模拟较慢的CXL内存。
4
Alberto Lerner, Gustavo Alonso:
CXL and the Return of Scale-Up Database Engines.
Proc. VLDB Endow. 17(10): 2568-2575 (2024)
CXL优势:
- 充分利用PCIe带宽
- 软件的简洁性
- 提供从 CPU 到加速器(计算设备)的路径
- 提供不同服务器组件之间的路径,例如从 NIC 到 SSD
RDMA 仅支持访问分解的内存,而 CXL 允许分解整个机架,而无需设备在物理层支持除 PCIe 之外的任何其他接口
- 共享内存架构
- 扩展可用内存空间
- 要求数据库在多层内存中处理数据放置于数据访问模式匹配的问题
- 内存池化(避免内存搁浅,提高资源利用率)
- 利用CXL交换机让不同设备的CPU访问整个内存池
- 要求数据库提高弹性,判断哪些数据应该放在本地内存,哪些数据应该放在共享内存,以及考虑动态负载下的内存分配问题
- 内存共享
- 不同机器的计算任务共享相同的内存和存储空间,可以构建更大规模的数据库系统
- 可能可以设计新的排序和散列算法、索引、一致性处理、更大规模的数据库系统中复杂查询任务的资源调度算法
- 扩展可用内存空间
- 近数据计算
- cxl控制器可能拥有计算能力,可作为近数据计算加速器
- cxl控制器可以提供更复杂的虚拟内存,不是简单地映射物理内存,而是提供一些隐式的数据移动和计算能力
- 新的异构架构
- CXL可以促进不同计算单元(如CPU、GPU、FPGA等)之间的协同工作,构建更加灵活和高效的异构计算平台。针对特定的工作可以设计新的异构架构
5
Minseon Ahn, Thomas Willhalm, Norman May, Donghun Lee, Suprasad Mutalik Desai, Daniel Booss, Jungmin Kim, Navneet Singh, Daniel Ritter, Oliver Rebholz
An Examination of CXL Memory Use Cases for In-Memory Database Management Systems using SAP HANA
Proc VLDB Endow 17(12) 3827-3840 (2024)
研究了在真实企业内存数据库系统中部署cxl的性能影响。
CXL用于两个用途:
- 动态内存扩展
- 快速故障转移
用FPGA实现了一个 cxl 3.0 原型。通过在CXL内存上创建dax文件系统并设置存储路径为该文件系统,将一个支持NVM的内存数据库系统(SAP HANA)部署在cxl内存上。
对于双计算节点、单内存池的计算节点故障转移,本文不考虑两个计算节点同时访问内存的情况,只考虑单个计算节点故障转移的场景。
将主数据存在CXL:
事务型工作流本身存在大量锁争用,瓶颈不在内存带宽和延迟,部署到CXL性能下降很小。分析型工作流,需要分类讨论。对于顺序访问较多的,通过预读/写可以实现较小的性能下降。对于随机访问较多的,性能下降较大。
将临时表存在CXL:
临时表容量大,容易造成内存空间不足,放到CXL内存中可以避免每个节点本地内存的超量配置。
在CXL内存中分配临时表的性能影响主要取决于CXL通信量和相应工作负载中的事务干扰(事务的锁争用导致带宽利用不足)。此外,对CXL内存的随机访问更容易受到内存延迟的限制,从而导致性能下降。
CXL内存用于故障转移:
用类似NVM的方式使用CXL共享内存,两个计算节点连接到同一个CXL内存设备。一个计算节点崩溃后,另一个计算节点直接用前一个计算节点的内存数据恢复数据库。SAP HANA本身NVM,因此可以直接支持这种功能。
本文局限性:完全没有考虑两个计算节点同时访问内存的情况。只允许一个节点访问内存,把CXL内存当作类似NVM的远程较慢的内存使用。
6
Seung Won Yoo, Joontaek Oh, Myeongin Cheon, Bonmoo Koo, Wonseb Jeong, Hyunsub Song, Hyeonho Song, Donghun Lee, Youjip Won:
DJFS : Directory-Granularity Filesystem Journaling for CMM-H SSDs.
FAST 2025: 35-51
传统文件系统的日志机制存在以下问题:
- 事务上的锁争用
- 事务锁本身的延迟
- 事务之间的冲突
- 串行事务提交
应用CXL可以用缓存行为粒度提交事务,但是实际收益很小,因为更快和细粒度的事务提交造成了更高的事务锁开销。
CXL SSD 与NVM相似,但是有一些不同点:
- 它既可以提供持久性内存的接口,也可以提供块设备的接口
- 它对访问局部性敏感,ssd内部有一个数GB的小缓存,能够加速对热点数据的访问。当数据访问不具备局部性/工作集过大时,缓存行粒度的访问不再具备优势。
本文解决方案:
按照目录粒度定义事务,最小化事务冲突和事务锁。同时不牺牲批量提交事务的优势(相比于按文件为粒度的事务定义,主要来自应用程序倾向访问专用目录的特性)。
设计较小的ssd区域用作事务区域,使用内存语义进行访问,充分利用CXL ssd性能。
7
Zhao Wang, Yiqi Chen, Cong Li, Yijin Guan, Dimin Niu, Tianchan Guan, Zhaoyang Du, Xingda Wei, Guangyu Sun:
CTXNL: A Software-Hardware Co-designed Solution for Efficient CXL-Based Transaction Processing.
ASPLOS (2) 2025: 192-209
解决的问题:
分布式事务性能不佳,有两个原因:节点之间数据传输网络栈开销高、传统的节点之间数据传输不具备缓存一致性,因此节点需要避免缓存远程数据或者复杂的软件一致性协议,导致额外开销。
机遇:
CXL提供低延迟远程数据传输和硬件支持的缓存一致性
本文的架构:
多个拥有本地内存的计算节点连接到一个支持硬件缓存一致性的CXL内存池,将共享数据结构(包括索引、锁和元组)放置在内存池当中,允许工作节点以多线程方式运行事务
直接在CXL内存执行分布式事务无法解决上述问题:
- 原因 1:为保持多节点的cpu缓存一致性,远程缓存信令会给CXL内存池访问带来相当大的性能开销。
- 原因 2:集中式监听过滤器导致传统支持硬件一致性的 CXL 原语的可扩展性问题。
insight:
实际应用中事务实际不需要这么高的一致性。举例:键值存储中的数据由两部分:数据和元数据。元数据包含索引、每个kv的锁等等。数据就是kv本身。在这样的键值存储中,只有修改元数据需要严格的硬件缓存一致性,修改数据不用那么高的一致性,因为应用层的并发控制算法可以保证不会读写正在被修改的不完整的数据。–> 要点:事务处理系统允许数据部分字段访问在时间上不连贯。
解决方案:用一个硬件代理实现了松散一致性的原语。用硬件维护每个内存位置对于不同节点的不同版本“视图”,对于不需要时刻保持一致的数据,每个节点修改本地视图再广播到其他节点
8
Chengsong Tan, Alastair F. Donaldson, John Wickerson:
Formalising CXL Cache Coherence.
ASPLOS (2) 2025: 437-450
形式化验证,和我的研究方向差距较大,暂时没有细读
9
Yan Sun, Jongyul Kim, Zeduo Yu, Jiyuan Zhang, Siyuan Chai, Michael Jaemin Kim, Hwayong Nam, Jaehyun Park, Eojin Na, Yifan Yuan, Ren Wang, Jung Ho Ahn, Tianyin Xu, Nam Sung Kim:
M5: Mastering Page Migration and Memory Management for CXL-based Tiered Memory Systems.
ASPLOS (2) 2025: 604-621
解决了CXL为基础的分层内存系统中页面迁移和内存管理的效率与精度问题。传统的CPU驱动页面迁移方案在识别“热页面”时存在精度不足、性能开销大、无法区分稀疏/密集热页面等问题,导致迁移效果有限甚至影响应用性能。
核心insight:
- 传统方案常将只包含稀疏的少量热字节的“温页面”误判为“热页面”,且对稀疏热页面的迁移会造成缓存污染和内存浪费。
- 识别热页面的性能开销本身可能抵消迁移带来的性能提升,尤其对延迟敏感应用影响显著。
- CXL控制器具备近内存处理能力,可在硬件层面精确统计每个页面和字的访问次数,为热页面识别和迁移提供更高效、低开销的支持。
主要方法:
- 提出并实现了M5平台,包括硬件级的页面/字访问计数器(PAC/WAC)、热页面/热字追踪器(HPT/HWT),以及用户空间的M5-manager软件接口。
- PAC/WAC在FPGA实现的CXL设备中,能精确统计每个4KB页面和64B字的访问次数,解决了传统采样/模拟方法精度不足的问题。
- 热点页面跟踪器 HPT/ 热点词跟踪器 HWT 采用Count-Min Sketch 等流式算法,低成本、高效率地在线追踪top-K热页面/热字,支持区分稀疏与密集热页面。
- M5-manager结合硬件计数器和系统带宽等指标,指导页面迁移策略,支持灵活、智能的迁移决策。
10
Yibo Huang, Haowei Chen, Newton Ni, Yan Sun, Vijay Chidambaram, Dixin Tang, Emmett Witchel
Tigon A Distributed Database for a CXL Pod
OSDI 2025 109-128
本文主要解决了分布式事务型数据库在多主机环境下高效同步和并发控制的问题。传统分布式数据库通过网络进行跨主机数据访问同步,导致大量消息交换和高延迟,尤其在多分区事务场景下性能急剧下降。现有RDMA等技术虽有提升,但仍远不及本地DRAM的访问效率。
有什么 insight?
CXL内存的新机会:利用新兴的CXL(Compute Express Link)内存技术,主机可直接通过内存总线访问共享内存,延迟远低于网络和RDMA。 活跃元组集合(CAT):实际并发事务同时跨主机访问的数据量很小(如每事务几十个元组),只需将这部分“活跃元组”放入CXL共享内存即可,大部分数据仍可留在本地DRAM。 同步需求分离:高频同步元数据(如锁、索引)放在硬件缓存一致(HWcc)区域,普通数据放在软件缓存一致(SWcc)区域,最大化CXL内存利用率。 避免2PC协议:通过CAT和CXL内存的原子操作,单主机即可完成事务所有修改和日志记录,无需昂贵的两阶段提交(2PC)。
用了什么方法?
数据动态迁移:数据初始分区存放于各主机DRAM,跨主机访问时按需迁移到CXL内存,事务结束后根据访问模式再迁回本地。 软件缓存一致协议:针对CXL内存硬件缓存一致区域有限的问题,设计了软件缓存一致协议,结合数据库自身的同步机制(如锁),保证SWcc区域的数据一致性。 高效并发控制:改进2PL和next-key locking协议,结合CXL内存的原子操作,实现跨主机高效同步和串行化,无需2PC。 可扩展日志与恢复机制:采用基于epoch的分组提交和并行日志记录,保证高吞吐和快速恢复。 优化数据替换策略:采用CLOCK算法替代LRU,降低元数据维护开销,提升HWcc区域利用率。 快捷指针优化:主机维护指向CXL元组的快捷指针,减少索引查找开销。
11
Jian Zhang, Yujie Ren, Marie Nguyen, Changwoo Min, Sudarsun Kannan:
OmniCache: Collaborative Caching for Near-storage Accelerators.
FAST 2024: 35-50
主要解决的问题:
OmniCache 针对近存储加速器(如智能SSD、CXL设备)在 I/O 和数据处理过程中,传统方案未能充分利用主机和设备两级缓存,导致数据移动开销大、处理延迟高、并发能力弱等问题。现有系统要么没有缓存支持,要么只用主机缓存,无法协同利用设备缓存,且缺乏动态的处理任务分配机制。
核心 insight:
- 近缓存原则(Near-cache): 优先在距离数据最近的缓存(主机或设备)进行 I/O 和处理,减少数据移动。
- 协同缓存(Collaborative Caching): 主机和设备缓存并行协作,提升带宽和并发性,减少因缓存驱逐导致的应用阻塞。
- 动态模型驱动的任务分配(Dynamic Offloading): 根据实时硬件和软件指标(如数据分布、带宽、队列延迟等),智能决定处理任务在主机或设备执行,提升整体效率。
- 利用 CXL.mem 技术,实现主机与设备缓存的直接协同
采用的方法:
实现了一个主机内存和设备内存的协同缓存机制。
- 同一数据块只存在于主机缓存或设备缓存之一,避免重复和一致性维护的开销。
- 避免主机缓存满时的应用等待,当主机缓存满时,新的数据会直接写入设备缓存,同时后台线程驱逐主机缓存中的旧数据,减少应用阻塞
- 通过 OmniIndex(区间树结构),主机统一管理两级缓存的数据分布和状态,实现高效查找和并发访问
- 应用线程可同时访问主机和设备缓存中的不同数据块,提升整体带宽和并发性
12
Haoyang Zhang, Yuqi Xue, Yirui Eric Zhou, Shaobo Li, Jian Huang:
SkyByte: Architecting an Efficient Memory-Semantic CXL-based SSD with OS and Hardware Co-design.
HPCA 2025: 577-593
主要解决的问题: 本文针对CXL(Compute Express Link)接口下SSD作为主存扩展时的性能瓶颈,尤其是由于闪存访问延迟高、垃圾回收等不可预测事件导致的CPU长时间停顿,以及CXL接口的字节级访问与闪存物理页级访问之间的粒度不匹配,造成大量无效I/O流量和性能损失。
核心insight:
仅将SSD当作主存扩展会导致严重的性能下降,主要原因是闪存访问延迟远高于DRAM,且现有OS和硬件无法有效隐藏这种延迟。 CXL接口支持字节级访问,但闪存只能页级访问,导致DRAM缓存空间浪费和写放大。 通过软硬件协同设计,可以显著提升CXL-SSD的性能和资源利用率。 采用的方法:
软硬件协同设计:SkyByte通过主机操作系统与SSD控制器协同,解决长延迟访问时的CPU停顿问题。SSD控制器检测到长延迟后,通过CXL协议向主机发送延迟提示,触发硬件异常,OS调度器进行线程切换,提升CPU利用率。 SSD DRAM缓存重构:将SSD内部DRAM分为缓存行级写日志和页级数据缓存,写操作先进入写日志,后台合并后再写入闪存,减少无效I/O和写放大。 自适应页迁移:识别热点页并迁移到主机DRAM,利用主机内存扩展SSD缓存能力,提升数据访问性能。 仿真与原型验证:基于MacSim和SimpleSSD搭建仿真平台,并在FPGA原型上验证关键机制。
13
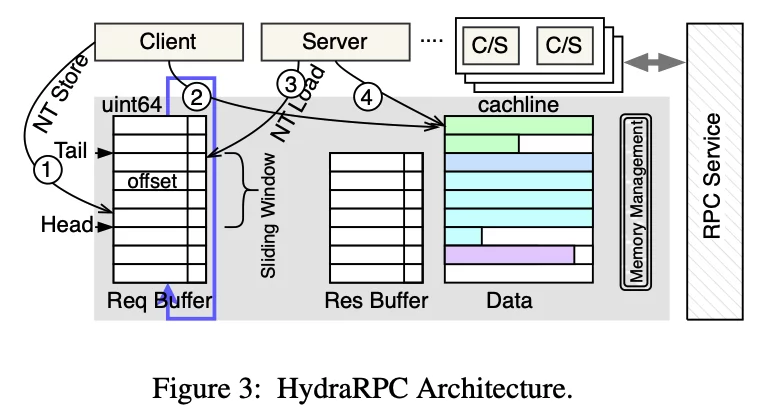
Teng Ma, Zheng Liu, Chengkun Wei, Jialiang Huang, Youwei Zhuo, Haoyu Li, Ning Zhang, Yijin Guan, Dimin Niu, Mingxing Zhang, Tao Ma:
HydraRPC: RPC in the CXL Era.
USENIX ATC 2024: 387-395
主要解决的问题
本文针对分布式系统中远程过程调用(RPC)通信的性能瓶颈,尤其是网络延迟、数据拷贝和序列化/反序列化开销,提出了新的解决方案。传统RPC依赖网络消息传递,受限于网络带宽和延迟,难以满足高性能和高扩展性的需求。
Insight
CXL(Compute Express Link)带来的内存共享能力,为多台服务器之间的数据传输提供了新的范式。利用CXL HDM(Host-Managed Device Memory),可以实现跨节点的共享内存访问,极大减少了网络通信和数据拷贝的开销。
RPC协议可以基于共享内存重构,不再依赖传统的消息传递和网络堆栈,从而实现更低延迟和更高吞吐量。 非缓存共享和零拷贝数据布局,结合滑动窗口和免忙轮询通知机制,进一步优化了性能和资源利用。
方法
HydraRPC架构:利用CXL HDM实现跨节点共享内存,RPC请求和响应通过共享内存队列传递引用,数据直接在共享内存区读写,避免网络传输和数据拷贝。
非缓存共享机制:通过MTRR设置和非时序访问指令(如clflush、ntstore),确保数据直接读写CXL HDM,绕过本地CPU缓存。
高效通知机制:采用SSE3的monitor/mwait指令优化轮询,降低CPU占用;未来支持PCIe MSI中断进一步提升通知效率。
滑动窗口协议:控制并发请求数量,防止内存访问拥塞,提高吞吐量和扩展性。
内存管理优化:消息队列和数据区分离管理,采用两级分配器,减少内存碎片和管理开销。
备注:
SSE3 的 monitor/mwait 指令是一种用于优化内存轮询(polling)的 CPU 指令集扩展,主要作用是降低轮询时的 CPU 占用和能耗。
原理简述:
monitor 指令:让 CPU 监控某个内存地址(通常是消息队列中的标志位)。
mwait 指令:让 CPU 进入低功耗等待状态,直到被监控的内存地址发生变化(即有新请求或响应到达)。
优势:
避免传统忙轮询(busy polling)不断读取内存导致高 CPU 占用。当有数据到达时,CPU会被唤醒,及时处理请求或响应。
14
Xu Zhang, Ke Liu, Yuan Hui, Xiaolong Zheng, Yisong Chang, Yizhou Shan, Guanghui Zhang, Ke Zhang, Yungang Bao, Mingyu Chen, Chenxi Wang:
DRack: A CXL-Disaggregated Rack Architecture to Boost Inter-Rack Communication.
USENIX ATC 2025: 1261-1279
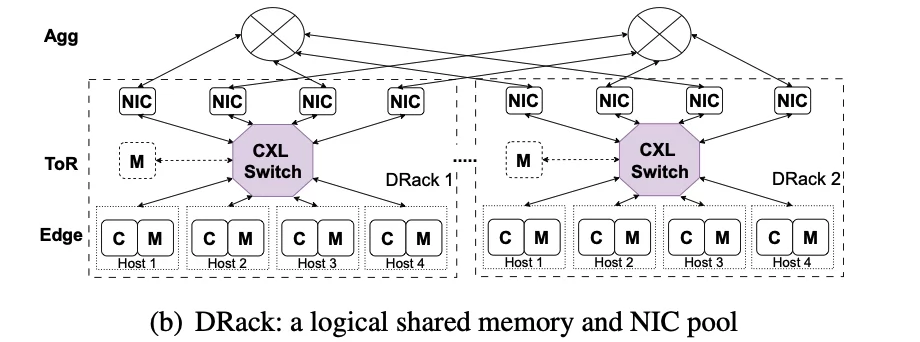
非常有创意的工作,把多个网卡接入CXL交换机,为每个主机动态分配网卡,最大化机柜之间的带宽利用率。
15
CXL Memory Performance for In-Memory Data Processing
VLDB 2025
分析了一个多socket的单服务器连接到包含多个cxl设备(cxl1.1)的内存池的架构下内存数据库系统 Hyrise 的性能。
主要insight:
- CXL扩展内存可以显著降低服务器内存硬件成本,并突破传统CPU本地内存容量限制。
- 数据库系统若能根据访问模式和频率合理分配数据到CXL或CPU本地内存,可在性能损失有限的情况下将大部分数据存储在CXL内存中。
- 带宽受限的工作负载(如高并发写入、SIMD列扫描)可通过多CXL设备扩展带宽获得性能提升;而延迟敏感的随机访问则更适合放在CPU本地内存。
- 热数据放在CPU内存,冷/温数据放在CXL内存,能兼顾性能和成本。
采用的方法:
- 设计并实现了CXL-Bench微基准测试框架,系统评估了CXL内存的访问带宽、延迟、扩展性等基本特性。
- 通过实验分析了数据库常见操作(如向量化列扫描、B+树索引操作)在不同数据分布(CPU/CXL/多CXL设备)下的性能表现。
- 在开源内存数据库Hyrise上,采用不同数据分布策略(如按访问频率分列放置、页级轮询分布等),运行TPC-H分析型负载,量化了实际查询性能和成本收益。
- 利用硬件性能分析工具(如Intel VTune TMA)深入分析了不同工作负载的内存瓶颈(带宽/延迟)。
具体测试方法:
- 将 CXL 设备配置为独立的 NUMA 节点,使用 Linux 的 mbind 系统调用,将数据库的数据(如表的某些列、索引节点、页等)分配到指定的 NUMA 节点(即 CXL 内存)。
- 利用 C++ 标准库的 polymorphic memory resource(PMR)机制,开发了内存数据库使用的自定义分配器。分配器在初始化时预分配一大块内存,并根据配置将其分布在 CPU 内存和 CXL 内存(可按页轮询、加权分布等策略)。
- 数据分布策略:支持按列分布(如热列在 CPU,冷列在 CXL)、按页分布(轮询或加权分布到不同内存类型)。 可根据访问频率统计,自动将最常访问的数据分配到本地内存,其他数据分配到 CXL。
16
Joonseop Sim, Soohong Ahn, Taeyoung Ahn, Seungyong Lee, Myunghyun Rhee, Jooyoung Kim, Kwangsik Shin, Donguk Moon, Euiseok Kim, Kyoung Park
Computational CXL-Memory Solution for Accelerating Memory-Intensive Applications
HPCA 2024 615
主要解决的问题:
本文针对CXL(Compute Express Link)内存扩展技术在数据密集型应用(如KNN搜索)中的带宽瓶颈问题,提出了新的架构。传统CXL虽然能实现内存池化和扩展,但物理带宽远低于主机DDR,严重限制了大规模数据处理性能。
主要insight:
- 仅靠CXL扩展内存无法解决带宽瓶颈,必须在内存侧进行近数据处理(NDP),减少数据在主机和内存间的移动。
- 通过硬件级负载均衡和优化的MAC运算单元,可以最大化内存内部带宽利用率,显著提升系统性能和能效。
- 内存分离架构结合NDP,能实现更高的资源利用率和更低的总拥有成本(TCO)。
采用的方法:
- 构建了基于CXL的原型系统(CMS),在CXL内存中集成NDP引擎,实现KNN等数据密集型任务的内存侧处理。
- 设计了硬件负载均衡器(LB),自动将数据均匀分布到多个DDR通道,提升带宽利用率,减少主机负担。
- 优化了MAC(Multiply-Accumulate Unit,乘加单元)运算单元,通过多层缓冲和流水线设计,隐藏累加器延迟,实现高吞吐FP32运算。
- 提供了基于Apache Arrow的软件库,方便数据分析平台调用CMS的内存和NDP功能。
本文具体执行的KNN任务是: 使用KNN算法对数据库中的特征向量进行最近邻搜索。每个特征向量为256维FP32类型。系统接收查询向量后,在百万级数据库特征向量中,计算并找出与查询向量最相似的25个条目(即K=25),返回结果给主机。
本文的硬件负载均衡器(LB)通过在硬件层面自动将数据以64字节为单位分布到多个DDR内存通道,实现高效的带宽利用。
具体做法如下:
- LB逻辑集成在CMS卡内部,无需主机CPU参与数据分配。
- 当数据通过CXL接口写入内存时,LB会将连续地址的数据交错分配到不同的内存通道,而不是集中在某一个通道。
- 这样可以让NDP引擎同时利用所有通道的带宽,避免单通道瓶颈。
- LB以DDR访问粒度(64字节)进行分配,最大化并行访问能力。
- 这种硬件自动分配方式比软件手动分配更高效,减少了主机负担和软件开销。
本文用fpga进行了验证。
17
Ruili Liu, Teng Ma, Mingxing Zhang, Jialiang Huang, Yingdi Shan, Zheng Liu, Lingfeng Xiang, Zhen Lin, Hui Lu, Jia Rao, Kang Chen, Yongwei Wu:
DSA-2LM: A CPU-Free Tiered Memory Architecture with Intel DSA.
USENIX ATC 2025: 1213-1222
主要解决的问题:
本文针对异构分层内存(如DRAM+CXLNVM)系统中,数据迁移过程的高CPU开销和迁移效率低下问题。传统分层内存系统在热冷数据检测和页面迁移时,需大量CPU参与,导致性能瓶颈和应用干扰。
核心 insight:
- 利用 Intel Data Streaming Accelerator (DSA) 硬件,实现“CPU-Free”页面迁移。DSA能以远高于CPU的带宽和更低的延迟完成内存区域间的数据移动,显著降低CPU负载。论文发现,只有合理设计迁移粒度、批量大小和并发度,才能充分发挥DSA优势。
主要方法:
- 在 Linux 内核中设计并实现 DSA-2LM 分层内存系统。
- 采用硬件性能计数器(PEBS)进行页面热度检测,结合 MEMTIS 的直方图算法。
- 页面迁移流程中,针对4KB普通页和2MB大页,设计自适应聚合算法,批量并发利用多个DSA通道。
- 动态调整批量大小和工作队列(WQ)数量,优化迁移效率。
本文标题是CPU-Free,实际上cpu还是需要执行少量的决策,例如迁移的起始地址、目标地址等。整个迁移过程卸载到硬件。对于正在进行的迁移,内核会临时将迁移页面的访问权限设置为只读或不可访问,防止数据不一致。迁移完成后,内核会更新页表,将页面映射到新位置,保证后续访问的是最新数据。
Intel Data Streaming Accelerator (DSA) 硬件类似一个功能扩展的dma引擎,采用多队列机制,应用或内核通过内存映射IO提交任务描述符,任务完成后通过 MSI-X 中断通知软件层。
DSA支持:
- 数据搬运:在不同内存区域间高速拷贝数据,无需CPU参与。
- 数据转换:支持内存填充、校验、压缩等操作。
- 异步处理:通过硬件队列(Work Queue, WQ)并发处理多个数据任务。
18
Zhisheng Hu, Pengfei Zuo, Yizou Chen, Chao Wang, Junliang Hu, Ming-Chang Yang:
Aceso: Achieving Efficient Fault Tolerance in Memory-Disaggregated Key-Value Stores.
SOSP 2024: 127-143
本文针对内存分离(Disaggregated Memory, DM)架构下的键值存储(KV Store)系统,提出高效容错机制。现有方案多采用复制实现容错,导致高内存空间和性能开销,限制了DM架构KV存储的应用和发展。
主要insight:
- 对于索引部分,采用检查点(checkpointing)机制能有效减少同步复制带来的性能损耗。
- 对于KV数据部分,采用纠删码(erasure coding)能显著降低空间开销。 因此,索引用检查点,KV数据用纠删码,混合容错机制最优。
采用的方法: 提出Aceso系统,采用如下创新设计:
- 索引检查点+版本恢复:用差分检查点减少带宽消耗,结合版本号恢复最近更新,保证一致性和高效恢复。
- KV数据纠删码+空间回收:采用XOR型纠删码,离线批量编码,利用线性特性实现高效空间回收(delta-based reclamation),并优化故障恢复流程(分层恢复)。
- 系统优化:本地索引缓存、RDMA相关优化等。
本文主要针对RDMA,只在背景部分涉及CXL,指出本文方法可以为CXL系统提供参考。
19
Yupeng Tang, Ping Zhou, Wenhui Zhang, Henry Hu, Qirui Yang, Hao Xiang, Tongping Liu, Jiaxin Shan, Ruoyun Huang, Cheng Zhao, Cheng Chen, Hui Zhang, Fei Liu, Shuai Zhang, Xiaoning Ding, Jianjun Chen:
Exploring Performance and Cost Optimization with ASIC-Based CXL Memory.
EuroSys 2024: 818-833
本文针对数据中心内存密集型应用面临的内存容量和带宽瓶颈,研究了基于ASIC的CXL(Compute Express Link)内存扩展在实际数据中心场景中的性能和成本优化问题。现有研究多基于仿真或FPGA,缺乏对真实ASIC CXL硬件的系统性评估,且对CXL内存扩展的实际成本效益和应用场景理解有限。
主要insight
- CXL内存不仅仅是“慢速分层内存”:即使本地内存带宽未满载,将部分负载迁移到CXL内存可缓解DDR通道带宽争用,整体降低访问延迟,提升应用性能。
- 远程Socket访问CXL性能下降明显:跨Socket访问CXL内存会导致高延迟和带宽损失,需避免。
- 智能调度和热页迁移策略能显著提升性能:合理的页分布和热页提升策略可最大化CXL内存效益。
- CXL扩展可显著降低数据中心TCO:通过抽象成本模型,证明CXL内存扩展能减少服务器数量和总体拥有成本。
采用的方法
- 在真实的ASIC CXL硬件平台上,针对多种数据中心应用(如KeyDB、Spark SQL、LLM推理等)进行性能测试。
- 内存分布策略:评估不同内存分布(MMEM/CXL/SSD、不同比例交错、热页迁移)对应用性能的影响。
- 抽象成本模型:提出可量化CXL内存扩展带来的TCO节省的模型,便于实际部署决策。
Yubo Liu, Yuxin Ren, Mingrui Liu, Hongbo Li, Hanjun Guo, Xie Miao, Xinwei Hu, Haibo Chen:
Optimizing File Systems on Heterogeneous Memory by Integrating DRAM Cache with Virtual Memory Management.
FAST 2024: 71-87
本文针对异构内存(DRAM+PM)架构下文件系统的性能瓶颈,分析了现有基于缓存(如VFS page cache)和DAX(Direct Access)两类主流设计的不足,发现它们都因数据搬运和同步开销过大而无法充分发挥DRAM缓存的优势,导致性能不理想。
Insight
- DRAM缓存仍有巨大价值:即使DAX能直接访问PM,DRAM与PM之间的性能差距依然显著,且DAX丢失了数据局部性带来的性能提升。
- 数据搬运和“cache tax”是关键瓶颈:应用与缓存之间的数据拷贝,以及缓存与PM之间的数据同步/迁移,是影响性能的核心问题。
- 缓存框架应与虚拟内存管理深度融合:通过将DRAM缓存集成到虚拟内存管理中,可以消除冗余数据拷贝,并提升数据同步/迁移的并行性。
核心做法是:
- 统一地址空间:通过异构页表,应用和文件系统的数据都映射到同一虚拟地址空间,数据可以直接在应用和缓存之间“映射”而非“拷贝”。
- 页面附加机制(page attaching):应用读写时,直接将缓存页映射到应用缓冲区,实现零拷贝。只有在实际写入时才触发写时复制(COW),进一步减少不必要的数据搬运。
- 多版本与并行管理:缓存和PM之间的数据同步/迁移可以利用多版本机制,后台异步进行(如2阶段刷写、异步缓存未命中处理),不会阻塞前端I/O操作,从而提升并行性和整体性能。
本文仅在背景提及CXL,主要是为了举例说明异构内存。
20
Midhul Vuppalapati, Rachit Agarwal:
Tiered Memory Management: Access Latency is the Key!
SOSP 2024: 79-94
论文主要解决的问题:
本文针对分层(Tiered)内存架构下的内存管理,指出现有系统普遍采用“将最热页面放入默认(最低延迟)内存层”的页面放置策略,但忽略了实际运行时多并发请求导致的内存互连争用,使得默认层的访问延迟可能远高于硬件标称值,甚至高于其他层,导致性能远低于最优。
主要insight:
- 传统假设“默认层访问延迟始终最低”在高负载下并不成立,内存互连争用会显著提升延迟。
- 最优页面放置策略应动态平衡各层的实际(loaded)访问延迟,而不是简单地将热页面塞入默认层。
- 通过实时测量各层访问延迟,并根据延迟动态调整页面分布,可以显著提升整体系统性能。
采用的方法:
- 提出Colloid机制,核心原则是“平衡访问延迟”,即页面放置应使各层平均访问延迟尽量接近。
- 利用硬件计数器(如Intel CHA)低开销地测量各层队列占用和请求到达率,估算实时访问延迟。
- 如果默认层延迟低于其他层,则将热页面从其他层迁移到默认层(提升模式)。如果默认层延迟高于其他层,则将热页面从默认层迁移到其他层(降级模式)。
- 自适应数据迁移量,用二分法逐步逼近延迟平衡点。
- 根据页面的访问概率,优先选择一组页面,使其总访问概率不超过 Δp,且迁移总字节数不超过设定的迁移限额。
本文可适用于包含CXL在内的多层内存系统。但是不强制要求使用CXL。
21
Huaicheng Li, Daniel S. Berger, Lisa Hsu, Daniel Ernst, Pantea Zardoshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, Mark D. Hill, Marcus Fontoura, Ricardo Bianchini:
Pond: CXL-Based Memory Pooling Systems for Cloud Platforms.
ASPLOS (2) 2023: 574-587
针对公有云平台中“内存搁置”(memory stranding)导致的DRAM资源浪费和高成本问题,提出了如何在满足云服务高性能要求的前提下,通过内存池化技术提升DRAM利用率、降低硬件成本。
- 通过分析Azure生产集群数据,发现跨8-16个CPU插槽的小规模内存池即可获得大部分池化收益,同时保持较低的访问延迟。
- 利用机器学习模型,可以准确预测每个虚拟机(VM)所需的本地与池化内存分配,实现接近NUMA本地性能。
- 约50%的VM实际只使用了不到一半分配的内存,未使用部分可安全池化。
- 对预测失误,系统可实时监控并迁移VM,保证性能不受影响。
主要使用了以下CXL特性:
- CXL.mem协议:支持通过load/store指令直接访问池化内存,无需DMA或页错误,保证低延迟。
- 多头设备(Multi-Headed Device, MHD):外部内存控制器(EMC)通过多个CXL端口连接多个主机,实现多主机共享池化内存。
- Host-managed Device Memory (HDM) decoder:主机可动态管理和分配池化内存地址空间。
- CXL 2.0/3.0的热插拔与动态容量分配:支持池内存的动态分配和回收,提升资源利用率。
22
Shaobo Li, Yirui Eric Zhou, Hao Ren, Jian Huang:
ByteFS: System Support for (CXL-based) Memory-Semantic Solid-State Drives.
ASPLOS (1) 2025: 116-132
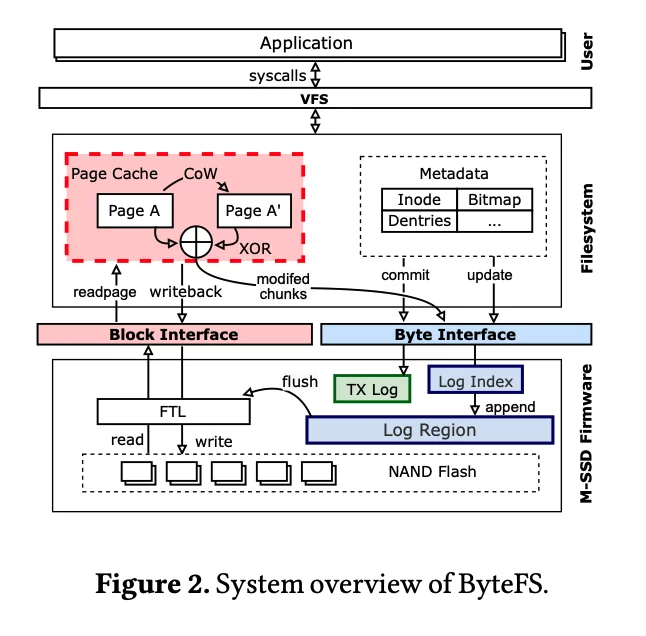
本文主要解决了如何为基于CXL的“内存语义SSD”(M-SSD)提供高效系统软件支持的问题。传统文件系统只支持块接口,无法充分利用M-SSD的字节/块双接口特性,导致I/O放大和性能损失。现有NVM文件系统也不适用于M-SSD,因为设备特性不同。
主要insight:
- M-SSD支持字节和块两种访问粒度,能以更低成本扩展存储容量,但系统软件需重新设计以发挥其优势。
- 文件系统的不同数据结构对访问粒度有不同需求,需灵活选择字节或块接口。
- 通过SSD固件和文件系统协同设计,可显著减少I/O放大和写入流量。
方法:
- 提出并实现了新文件系统ByteFS,支持字节/块双接口,适配M-SSD。
- 对文件系统核心数据结构进行访问粒度分析,指导接口选择。
- 在SSD固件中采用日志结构化管理DRAM,实现数据合并,减少对闪存的无效I/O。
- 主机与SSD缓存协同,优化内存资源利用。
- 支持事务和崩溃一致性,利用固件日志加速恢复。
23
Weigao Su, Vishal Shrivastav:
EDM: An Ultra-Low Latency Ethernet Fabric for Memory Disaggregation.
ASPLOS (1) 2025: 377-394
计算机网络强相关,暂时没有细读。
24
Yupeng Tang, Seung-Seob Lee, Abhishek Bhattacharjee, Anurag Khandelwal:
pulse: Accelerating Distributed Pointer-Traversals on Disaggregated Memory.
ASPLOS (1) 2025: 858-875
主要解决disaggregated memory架构下,指针遍历(pointer traversal)型数据结构(如链表、树、图等)在远程内存访问时面临的高延迟和低能效问题。
两方面加速:
- 远程内存中的近数据计算
- 利用可编程交换机加速跨内存节点的指针遍历跳转
本文可适用于CXL架构,但并未使用CXL的特性
25
Jinshu Liu, Hamid Hadian, Yuyue Wang, Daniel S. Berger, Marie Nguyen, Xun Jian, Sam H. Noh, Huaicheng Li:
Systematic CXL Memory Characterization and Performance Analysis at Scale.
ASPLOS (2) 2025: 1203-1217
本文主要分析了CXL内存(基于DRAM介质)的性能特征:
- 高负载(带宽利用接近饱和时)下CXL设备端容易出现请求排队,进而引发长尾延迟。
- 混合读写场景下,CXL设备吞吐量会随着读写比例变化而发生改变,不同CXL设备吞吐量最大的读写比不同。
- CXL+NUMA的尾部延迟更严重,跨Socket访问CXL设备会导致更高的延迟和更低的带宽。
- 传统的CPU预取策略在高负载下无法有效隐藏CXL设备延迟,因为CXL延迟较高,导致预取请求排队,反而导致了CPU停顿和延迟增加。
本文还提出了一个分析框架,对比应用程序运行在本地内存和CXL内存下的关键硬件计数器,可以定位CXL导致性能下降的根本原因(读性能/写性能/缓存预取导致的CPU停顿等)。
对数据库的一些启示:
- CXL设备在高带宽压力和混合读写场景下尾延迟更严重,数据库应优化访问模式,避免带宽饱和和频繁混合读写,或采用分批/异步处理机制
- 对于延迟敏感的数据结构或热数据,应优先放置在本地DRAM或低延迟CXL设备上,冷数据或大对象可放在高延迟CXL设备
26
Li Peng, Wenbo Wu, Shushu Yi, Xianzhang Chen, Chenxi Wang, Shengwen Liang, Zhe Wang, Nong Xiao, Qiao Li, Mingzhe Zhang, Jie Zhang:
XHarvest: Rethinking High-Performance and Cost-Efficient SSD Architecture with CXL-Driven Harvesting.
ISCA 2025: 434-449
本文是硬件架构设计的论文。解决的问题:
SSD 内部的计算资源和dram缓存往往为了应对突发流量需要过量配置,正常流量情况下存在资源浪费。本文建议ssd配置较少的资源,在流量突发时,利用CXL扩展使用宿主机的资源。本文还提出一套 主机-SSD统一元数据缓存 和 负载检测机制。
27
Juechu Dong, Jonah Rosenblum, Satish Narayanasamy:
Toleo: Scaling Freshness to Tera-scale Memory Using CXL and PIM.
ASPLOS (4) 2024: 313-328
利用 CXL 解决可信计算环境中的内存新鲜性(freshness)问题,暂时没有细读。
28
Henry N. Schuh, Arvind Krishnamurthy, David E. Culler, Henry M. Levy, Luigi Rizzo, Samira Manabi Khan, Brent E. Stephens:
CC-NIC: a Cache-Coherent Interface to the NIC.
ASPLOS (1) 2024: 52-68
研究如何在新型缓存一致性互连(如UPI、CXL)下,重新设计主机与网卡(NIC)之间的软件和硬件接口,以充分发挥缓存一致性互连的性能优势。
传统接口存在的问题:
- 高延迟:PCIe接口采用MMIO和DMA,数据传输需绕过CPU缓存,导致每次主机与NIC通信都要经过昂贵的总线往返,增加了包处理延迟。
- 数据结构分离:主机和NIC各自维护本地数据结构,更新和同步需要显式信号和多次通信,增加了开销。
- 信号机制低效:采用寄存器(head/tail)显式信号,需额外的PCIe事务,批量处理虽提升吞吐但进一步增加延迟。
- 缓冲管理繁琐:主机独立管理所有缓冲区,NIC无法参与优化,导致资源利用率低和额外的同步负担。
- 无法利用缓存一致性:PCIe不支持缓存一致性,无法实现主机与NIC间高效共享和同步数据。
本文提出的CC-NIC接口贡献与优势:
- 数据结构与信号机制优化:将信号内联到描述符中,减少额外的通信轮次,实现更高效的生产者-消费者同步。
- 充分利用缓存一致性互连:主机和NIC可直接共享数据结构,通过硬件协议自动同步,减少软件轮询和显式信号操作。
- 缓冲管理共享与回收:主机和NIC共同管理缓冲池,实现缓冲区回收和复用,提升缓存命中率和内存利用率,降低分配和释放开销。
- 高性能:显著降低包处理延迟(最低可降至PCIe的1/5),提升吞吐量(可达1.5Gpps、980Gbps),在高负载下优势更明显。
- 节省CPU资源:应用层可用更少的线程达到同样的网络性能,提升整体系统效率。
- 设计可扩展性:接口设计原则可推广到其他缓存一致性互连(如CXL、CCIX),适应未来硬件发展。
29
Hyungkyu Ham, Jeongmin Hong, Geonwoo Park, Yunseon Shin, Okkyun Woo, Wonhyuk Yang, Jinhoon Bae, Eunhyeok Park, Hyojin Sung, Euicheol Lim, Gwangsun Kim:
Low-Overhead General-Purpose Near-Data Processing in CXL Memory Expanders.
MICRO 2024: 594-611
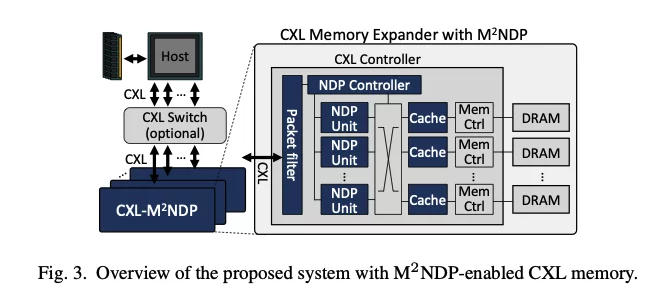
设计了一个用于通用近数据计算的CXL内存扩展器软硬件架构。完全兼容标准CXL协议,主机直接使用内存读写接口(CXL.mem)调用近数据计算。避免了使用 CXL.io/PCIe 进行传统卸载的高延迟开销。
将近数据计算函数调用封装到确定的地址,并在CXL存储器输入端过滤数据包,如果传入的内存访问地址与预先分配的专用内存范围相匹配,就触发近数据计算。
30
Houxiang Ji, Srikar Vanavasam, Yang Zhou, Qirong Xia, Jinghan Huang, Yifan Yuan, Ren Wang, Pekon Gupta, Bhushan Chitlur, Ipoom Jeong, Nam Sung Kim:
Demystifying a CXL Type-2 Device: A Heterogeneous Cooperative Computing Perspective.
MICRO 2024: 1504-1517
主要分析了 CXL Type-2 设备(主要为同时支持CXL.cache和CXL.mem的各种硬件加速器)的架构和性能特性。
- CXL Type-2设备支持硬件级主机-设备缓存一致性和统一内存空间,显著简化了编程复杂度,并提升了细粒度主机-设备数据交换的效率。
- 与PCIe和CXL Type-3设备相比,CXL Type-2设备在小数据量频繁传输场景下具有更低延迟和更高带宽,尤其适合数据中心延迟敏感应用。
- 通过硬件加速Linux内核特性(如zswap和ksm),CXL Type-2设备能有效降低主机CPU负载和应用尾延迟,优于传统CPU和PCIe设备方案。
31
Zhe Zhou, Yiqi Chen, Tao Zhang, Yang Wang, Ran Shu, Shuotao Xu, Peng Cheng, Lei Qu, Yongqiang Xiong, Jie Zhang, Guangyu Sun:
NeoMem: HardwareSoftware Co-Design for CXL-Native Memory Tiering
MICRO 2024 1518-1531
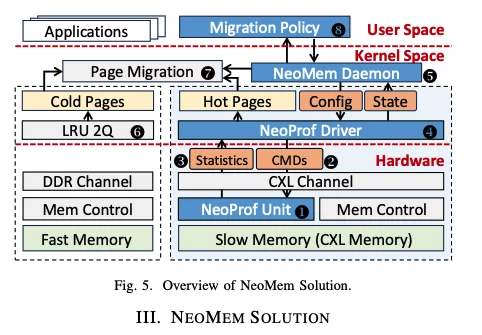
本文针对CXL异构内存系统中的高效分层管理问题,尤其是“热页”检测和迁移。现有方法由于内存访问分析分辨率低、开销大,难以实现高效的内存分层管理,导致系统性能受限。
Insight
- 利用CXL设备侧控制器的特殊架构,将内存访问分析从CPU端卸载到设备端,能极大提升分析精度和效率。
- 通过硬件直接监控真实的LLC(Last Level Cache)miss,避免传统方法只能感知TLB miss或依赖低频采样的局限。
- 结合硬件统计与操作系统动态策略,可实现更及时、准确的热页迁移,显著提升系统性能。
方法
- 硬件/软件协同设计:提出NeoMem方案,在CXL设备侧集成专用硬件分析单元NeoProf,实时统计内存访问热度、带宽利用率等信息。
- 高效热页检测:NeoProf采用改进的Count-Min Sketch算法,低成本高分辨率地检测热页,并通过热位过滤避免重复迁移。
- 动态迁移策略:操作系统根据NeoProf统计信息,动态调整热页阈值和迁移策略,兼顾带宽利用、迁移开销和误判率。
- 页面迁移后及时更新页表映射,确保地址翻译正确。
32
Oasis: Pooling PCIe Devices Over CXL to Boost Utilization
SOSP 2025
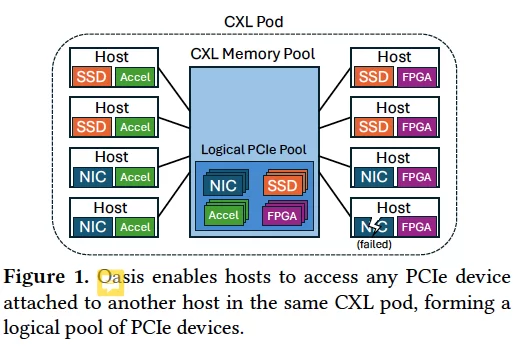
本文针对云平台中PCIe设备(如NIC和SSD)利用率低的问题,提出了如何通过软件方式在CXL内存池上实现PCIe设备池化,从而提升设备利用率、降低总拥有成本(TCO)的问题。传统的PCIe设备池化依赖昂贵且不灵活的PCIe交换机,本文提出一种无需硬件交换机、仅依赖现有CXL 2.0设备的解决方案。
有什么insight?
- CXL内存池已在数据中心部署用于提升内存利用率,利用同样的投资可以“顺便”实现PCIe设备池化,几乎零额外成本。
- PCIe设备(如NIC、SSD)在云平台中普遍存在分配过度、资源搁置和冗余容错导致的低利用率。通过池化可显著提升利用率。
- CXL 2.0设备虽然不具备跨主机缓存一致性,但PCIe设备通常通过DMA直接访问内存,可规避大部分一致性开销。
- 高性能消息通道设计是跨主机池化的关键,合理利用缓存失效和预取可大幅提升消息吞吐量。
具体提出了什么创新性的方法?
- Oasis系统架构:提出并实现了Oasis系统,允许多个主机通过CXL内存池共享PCIe设备。Oasis包含统一的数据面和控制面,支持多种PCIe设备类型(如NIC、SSD),通过专用engine扩展。
- 非一致性CXL内存上的高效消息通道:针对现有CXL 2.0设备不具备跨主机缓存一致性的问题,设计了一种高吞吐、低延迟的消息通道,利用缓存失效和预取优化,吞吐提升29倍。
- 数据面优化:充分利用PCIe设备DMA访问特性,避免不必要的缓存失效和写回操作,降低性能损耗。
- 容错与负载均衡机制:支持设备故障时毫秒级自动切换,以及实例间的动态负载迁移,提升可用性和资源利用率。
非一致性CXL内存上的高效消息通道具体是设计了一种预取与缓存失效结合的策略:
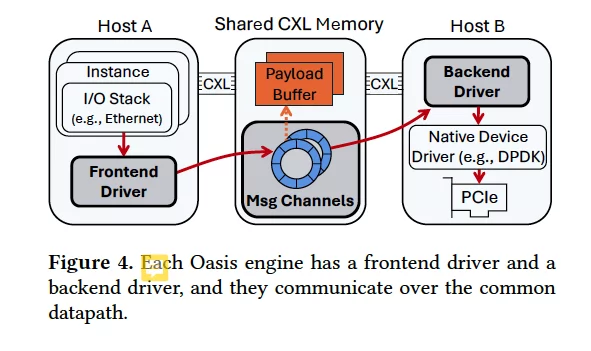
host之间通过环型缓冲区交互,接收方(图中的host B),需要主动执行智能的预取和缓冲区失效操作。
本文提出在非一致性CXL内存上,主动利用CPU缓存预取指令加速消息读取,同时在关键时刻主动失效(清除)缓存行,确保预取能获得最新数据。
- 预取:接收方在轮询消息通道时,使用软件预取指令(如PREFETCHT0)提前把后续缓存行加载到本地CPU缓存,加快消息读取速度。
- 缓存失效:由于CXL内存不一致,预取进来的缓存行可能是旧数据。Oasis设计让接收方在消费完一个缓存行后,主动对该缓存行执行失效操作(如CLFLUSHOPT),清除本地缓存,使后续预取能真正从CXL内存获取最新消息。
- 批量失效:如果一次预取了多个缓存行,发现有些缓存行是旧的,也会批量失效这些缓存行,保证后续预取有效。
我的简单理解:CXL2.0无法提供硬件级别的多host CPU缓存一致性,因此host要主动根据预取的数据的语义判断数据是否有效。依然可以通过预取获得性能提升(尽管预取的数据可能是旧的),只要在语义层面查到数据过于陈旧时主动使缓存失效就可以了。
33
Yan Sun, Yifan Yuan, Zeduo Yu, Reese Kuper, Chihun Song, Jinghan Huang, Houxiang Ji, Siddharth Agarwal, Jiaqi Lou, Ipoom Jeong, Ren Wang, Jung Ho Ahn, Tianyin Xu, Nam Sung Kim:
Demystifying CXL Memory with Genuine CXL-Ready Systems and Devices.
MICRO 2023: 105-121
评估了3种真实CXL扩展内存设备(不支持多host、更不支持多host之间的缓存一致性)的性能特性。与模拟CXL扩展内存(另一个NUMA node的DRAM)进行了对比。提出了一种非常简单的基于对多个硬件统计参数线性回归的CXL内存分配模型,预测每个时间窗口的最优CXL内存和本地内存比例。
34
Junhyeok Jang, Hanjin Choi, Hanyeoreum Bae, Seungjun Lee, Miryeong Kwon, Myoungsoo Jung:
CXL-ANNS: Software-Hardware Collaborative Memory Disaggregation and Computation for Billion-Scale Approximate Nearest Neighbor Search.
USENIX ATC 2023: 585-600
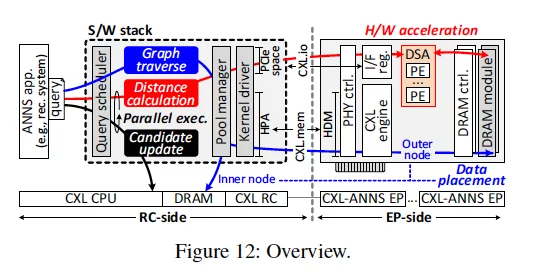
本文解决的问题:
CXL-ANNS 主要解决了大规模(十亿级)近似最近邻搜索(ANNS)在内存压力和性能瓶颈上的挑战。传统方法在准确性、扩展性和性能之间难以兼顾,尤其是数据量巨大时,现有压缩或分层存储方案要么牺牲准确率,要么查询延迟高。
主要 insight:
- 利用 CXL 技术实现内存池化和分离,让主机可以像本地 DRAM 一样访问大容量远程内存,突破单机内存瓶颈。
- 距离计算是 ANNS 的主要性能瓶颈,但计算本身简单,适合硬件加速和近数据处理。
- 节点访问有强烈的局部性,频繁访问的节点优先缓存到本地内存,减少远程访问延迟。
- 协同计算:让 CXL 端点设备(EP)负责距离计算,主机负责图遍历和候选更新,充分利用各自硬件资源。
- 预取和细粒度调度:通过算法感知预取和任务解耦,进一步隐藏远程内存访问延迟,提高并行度和资源利用率。
具体方法:
- 内存分离与池化:将所有数据集放入 CXL 内存池,主机通过 CXL RC 统一管理和访问。
- 关系感知缓存:用 SSSP 算法分析图结构,把高频访问节点缓存到本地 DRAM,其他数据放远程 CXL 内存。
- EP 端距离计算加速:在 EP 设备上实现专用硬件(DSA),直接在内存侧计算距离,只返回标量结果(计算后的距离信息),极大减少数据传输量。
- 向量分片与并行计算:将高维向量分片分布到多个 EP,距离计算并行进行,主机汇总结果。
- 预取与调度优化:主机根据候选数组预测下次访问节点,提前预取数据;任务调度上将候选更新与距离计算解耦,提高硬件利用率。(主机对计算结果进行排序、cxl内存内计算设备持续进行距离计算,这两个过程构成一个类似流水线的结构,同时充分利用主机和CXL扩展设备的计算性能)。
35
Shao-Peng Yang, Minjae Kim, Sanghyun Nam, Juhyung Park, Jin-Yong Choi, Eyee Hyun Nam, Eunji Lee, Sungjin Lee, Bryan S. Kim:
Overcoming the Memory Wall with CXL-Enabled SSDs.
USENIX ATC 2023: 601-617
研究如何使基于 Flash 的 CXL 内存扩展器达到接近 DRAM 的性能。本文主要提供一些系统和硬件设计建议,并提供大量实验数据。
- 提出:由于存在逻辑地址到物理地址的映射,用逻辑地址的规律来优化性能不可取
- 由于Flash和DRAM的粒度不同,对不同缓存行的访问可能重复读取同一个4KB块,因此在CXL ssd硬件上添加一个未命中状态保持寄存器,维护正在进行但尚未完成的请求的状态信息,避免重复读取同一块数据。
- 在SSD硬件添加预取器
- 建议使用延迟更低的SLC或ULLC闪存,并配置更大的DRAM缓存以减少对闪存的访问延长闪存寿命
36
Mingxing Zhang, Teng Ma, Jinqi Hua, Zheng Liu, Kang Chen, Ning Ding, Fan Du, Jinlei Jiang, Tao Ma, Yongwei Wu:
Partial Failure Resilient Memory Management System for (CXL-based) Distributed Shared Memory.
SOSP 2023: 658-674
解决的问题:
分布式共享内存到内存分配器难以处理部分计算节点故障的问题。
解决方案:
- 设计了一个分布式内存分配器,支持部分节点故障时的内存分配和回收。主要思路借鉴了风险指针,同时设计了一种基于纪元的内存回收机制,确保在节点故障时不会回收仍被其他节点引用的内存。
37
Sangjin Lee, Alberto Lerner, Philippe Bonnet, Philippe Cudré-Mauroux:
Database Kernels: Seamless Integration of Database Systems and Fast Storage via CXL.
CIDR 2024
提出一种“数据库内核(Database Kernel)”的概念,数据库内核运行在SSD上(近数据计算),对特定CXL内存地址范围的访问会触发内核代码执行。CXL设备不一定1:1地暴露DRAM地址空间,而是可以通过内核代码暴露虚拟的地址空间。可以支持一些高级功能,比如读写某个地址区间时触发数据压缩/解压缩,或者触发索引更新等。
本文用FPGA进行了简单实验,没有详细的性能分析。
38
Peiqi Yin, Qihui Zhou, Xiao Yan, Chao Wang, Eric Lo, Changji Li, Lan Lu, Hua Fan, Wenchao Zhou, Ming-Chang Yang, James Cheng:
CARINA: An Efficient CXL-Oriented Embedding Serving System for Recommendation Models.
Proc. ACM Manag. Data 3(3): 137:1-137:29 (2025)
本文面向的架构:
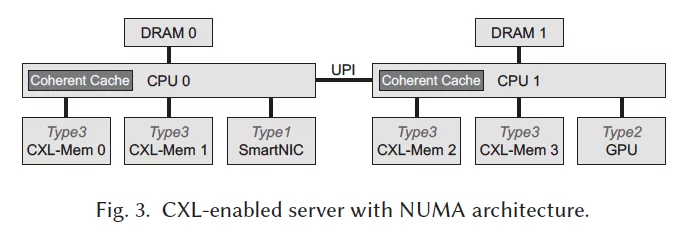
本文提出的系统架构:
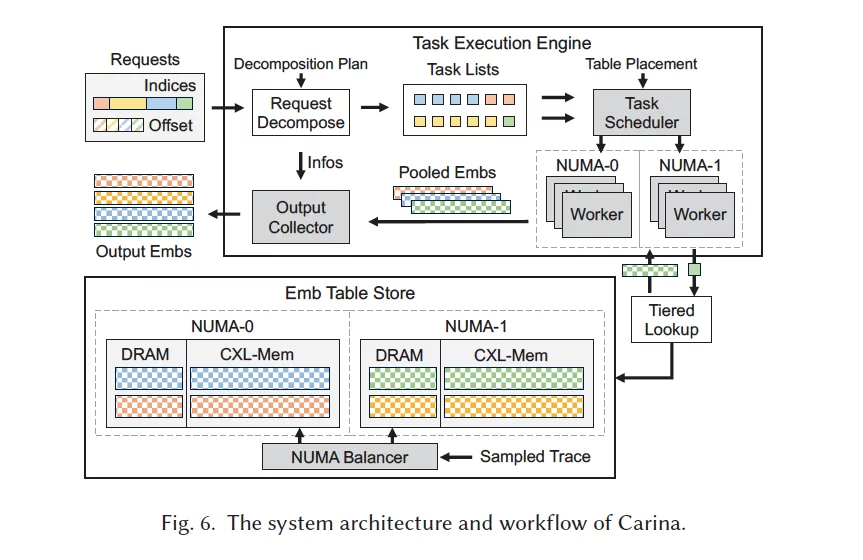
本文面向单服务器的场景优化,不涉及CXL交换机或多头CXL设备。
本文面向推荐系统的特殊工作流:存在多个(数百个)巨型数组,总共需要数TB的内存空间。每个任务包含一组请求,需要从指定的多个数组中读取多个数据条目(每个数组可以读取多个条目),只有获取到请求的所有条目才认为一次请求成功。
本文解决的问题:
本文针对嵌入式推荐模型(ERM)在推理服务时面临的内存瓶颈问题,尤其是在采用新型 CXL(Compute eXpress Link)异构内存架构时,传统基于 DRAM 的服务系统无法高效利用 CXL,导致 CXL 带宽拥塞成为系统性能瓶颈。
有什么 insight?
- CXL 适合 ERM embedding 服务,但直接用 DRAM 方案迁移到 CXL会因带宽低而性能骤降。 CXL 拥塞是核心问题:嵌入查找流量大,CXL 带宽远低于 DRAM,易被饱和。
- NUMA 架构进一步加剧带宽不均,跨 NUMA 节点访问 CXL/DRAM速度差异大。
- Embedding 访问高度偏斜:少量热点 embedding 占据大部分访问流量。 传统同步并行策略(intra-table)无法细粒度控制带宽使用,导致线程等待和带宽浪费。
Carina 系统设计了两大核心方法:
- 均衡 embedding 放置:
- 表级跨 NUMA 分片:每个 embedding table 完全分配到一个 NUMA 节点,避免远程访问。
- embedding 级 DRAM-CXL 分层:热点 embedding 存 DRAM,冷点存 CXL,按访问频率和带宽比例分配,充分利用两种内存带宽。
- 动态调整分布:访问模式变化时,后台迁移 embedding table,最小化数据移动。 本文具体的移动决策算法是比较简单的线性规划和启发式方法。
- 带宽感知任务执行:
- 异步任务并行:将请求批次拆分为细粒度任务,线程异步处理,避免同步等待。
- 带宽感知调度:实时监控 CXL 带宽利用率,动态选择任务,防止瞬时带宽饱和。
- MILP 优化任务拆分:针对不同 embedding table 的工作负载,离线求解(线性规划)最优任务大小,兼顾吞吐和延迟。
39
Irina Calciu, M. Talha Imran, Ivan Puddu, Sanidhya Kashyap, Hasan Al Maruf, Onur Mutlu, Aasheesh Kolli:
Rethinking software runtimes for disaggregated memory.
ASPLOS 2021: 79-92
提出使用硬件支持的基于缓存一致性的原语代替传统的基于swap和页面错误的透明的远程内存访问机制,从而大幅提升远程内存访问性能。本文提出的方法类似 CXL 的多头type-3设备缓存一致性机制,本文发表时间早于 CXL 3.0 标准的发布。
40
Huang, Yibo, et al. “Pasha: An efficient, scalable database architecture for cxl pods.” Proceedings of the Conference on Innovative Data Systems Research (CIDR). 2025.
本文是 Tigon (同一个作者)的早期版本,简单介绍了一个基于CXL共享内存的分布式数据库架构
Pasha 架构的核心思想如下:
- 分区+共享区混合架构:每个主机拥有自己的本地分区(存储于本地 DRAM),只负责本分区的数据读写;同时所有主机共享一个 CXL 内存区域(Shared Region),用于存放需要跨主机访问的数据。
- 动态数据迁移:当事务需要访问其他主机的数据时,将相关元组和元数据(如锁)从分区迁移到共享区,事务即可在本主机完成所有操作,避免多主机事务和 2PC 协议。
- 硬件缓存一致性优化:共享区分为硬件缓存一致(HWcc)和软件缓存一致(SWcc)两部分。高频同步的元数据(如锁、索引)放在 HWcc 区,普通数据放在 SWcc 区,最大化 CXL 内存利用率和性能。
- 单主机事务执行:通过上述机制,所有事务都能在单主机完成,采用单节点并发控制协议(如 2PL、MVCC),大幅降低跨主机同步和通信开销。
- 高可扩展性与弹性:架构支持高并发、容忍部分主机故障,并可利用 CXL 内存实现高效弹性扩展和数据迁移。
本文没有特别具体的实现(甚至论文提及的“动态数据迁移”在本文的实验中都没有真实实现),本文只是粗略地提出了整体架构和一些研究挑战。
主要读Tigon即可。